
Sınıflandırma Yöntemleri

İkili sınıflandırma (Binary classification) problemlerinde, sadece cevabı evet ya da hayır olan bir soru sorarız. Eğer verilecek cevap ikiden fazla değer içinden seçilerek cevaplanacaksa buna çok sınıflı sınıflandırma (multi-class classification) problemi deriz. Eğer tespit etmeye çalıştığımız sınıf birden fazla sınıfa sahip bir kümeden geliyorsa ve bu sınıflardan birden fazlasını aynı anda seçme ihtiyacımız varsa buna çoklu etiketli sınıflandırma (multi-label classification) adını veririz. Yukarıdaki örnekte gördüğünüz gibi resimde hem köpek hem çimen hem de doğanın aynı anda görüldüğü ve bunlardan herhangi birini seçmenin, diğerlerinin olmadığı anlamına gelmesinin yanlış olduğu durumlarda en doğru çıktıyı çoklu etiketli sınıflandırıcılar vermektedir. Hayatımızda sınıflandırma problemlerinin çok büyük bölümü birden fazla etiket ile sınıflandırma ihtiyacına sahip problemlerdir. Çoklu etiketli sınıflandırmanın amacı, tek bir örnek için bir dizi ilgili etiket ataması yapabilmektir. Bununla birlikte, yaygın olarak bilinen algoritmaların çoğu çok sınıflı sınıflandırma problemleri (çoklu etiketli değil) için tasarlanmıştır. Bu makalede, size çoklu etikelti sınıflandırma probleminin çözümü için farklı gerçekleme örnekleri sunulmaktadır. Bu amaçla, Scikit-multilearn kütüphanesinde bulunan çoklu etiketli sınıflandırma algoritma uyarlamaları ve Keras kütüphanesindeki derin öğrenme gerçeklemelerinden faydalanılmıştır. Kendinizin yapabileceği gerçeklemelerin yanında, Artiwise Analytics’in varsayılan olarak sunduğu çoklu etiketli sınıflandırma yeteneğini de görmüş olacaksınız. Böylece önemli bir ihtiyaç alanına sahip olan bu problemin farklı çözüm yöntemlerinde kıyaslaması yapılabilmektedir.
Makine Öğrenmesi (Machine Learning)
Klasik makine öğrenmesi algoritmaları olan istatistiksel ve olasılıksal modeller ile çoklu etiketli sınıflandırma problemlerine çözüm yolları üretmek mümkündür. Mevcut algoritmaların evrilerek bu probleme uyarlanmasında çeşitli yöntemler kullanılmaktadır:
- Problem dönüştürme yöntemleri (problem transformation methods), çoklu etiketli sınıflandırma problemini bir veya daha fazla geleneksel çok sınıflı sınıflandırma (multi-class) problemine böler.
- Problem uyarlama yöntemleri (problem adaptation methods), çoklu etiketli verilerle doğrudan başa çıkmak için çoklu sınıf sınıflandırma algoritmalarını genelleştirir. Örneğin, tek bir çoklu sınıf sınıflandırıcısının ürettiği çıktılardaki ihtimallere uygulanacak eşik değeri ile birden fazla sınıf etiketi seçilebilir.
- Topluluk yöntemleri (ensemble methods), önceki iki yaklaşımdan da faydalanarak bir çözüm üretir. Örneğin yukarıdaki iki farklı metodolojinin kullanıldığı çözüm çıktıları bir kural ya da öngörü ile birleştirilerek nihai sonuç üretilebilir.
Bu blog paylaşımında, yukarıdaki yöntemlerden problem dönüştürme yöntemi altında bulunan Etiket Gücü Kümesi (Label Powerset) kullanılmıştır. Bu yönteme göre, etiketlerin örnekler üzerinde karşılaşılan her kombinasyonu benzersiz bir kombinasyon numarasıyla eşleştirilir ve bu numaraların sınıf olarak kullanıldığı çoklu sınıf sınıflandırıcısı eğitilir.

Etiket Gücü Kümesi kullanmanın avantaj ve dezavantajlarına bakarsak :
Avantajları
- Etiket korelasyonları dikkate alınır.
Dezavantajları
- Yüksek hesaplama karmaşıklığına sebep olur.
- Birkaç örnekle ilişkili birden fazla sınıfla dengesiz veri kümesine yol açabilir.
Derin Öğrenme (Deep Learning)
Şu ana kadar en son teknoloji (state-of-the-art) çözümlerin pabucunu dama atmakta olan derin öğrenme yöntemlerinin boy göstermesi ile doğal dil işleme (NLP) algoritmaları altın çağına girmiştir.
Derin öğrenme, doğal dilin çoklu temsil seviyelerini öğrenmenin birçok faydasını getirir. NLP problemleri için derin öğrenmeyi kullanmanın birçok faydası vardır:
- Verilerden veya problemden doğrudan sınıflandırıcı türetilebildiği gibi, el yapımı bir özelliğin eksikliğini veya aşırı spesifikasyonunu da iyileştirir.
- Özelliklerin elle çıkartılması (feature engineering) genellikle çok zaman alır ve her görev veya etki alanına özgü sorun için tekrar tekrar çıkartılması gerekebilir. Bir alandan öğrenilen özellikler genellikle diğer alanlara veya etki alanlarına karşı çok az genelleme yeteneği gösterir. Aksine, derin öğrenme verilerden gelen bilgileri ve birçok seviyede temsili öğrenir, burada alt seviye, doğrudan veya ince ayarlardan sonra diğer alanlar tarafından kullanılabilen daha genel bilgilere karşılık gelir.
Sınıfların özelliklerine tamamen ayrık gibi davranmayan modeller ile öğrenmek, en yakın komşu veya kümeleme benzeri modellere göre çok daha verimli olabilir. Kelimeler bağımsız olarak ele alındığında, NLP sistemleri inanılmaz derecede kırılgan olabilir. Bu benzerlikleri sonlu bir vektör uzayında yakalayan dağılımsal temsil, bu yazıda anlatılacak NLP sistemine daha karmaşık akıl yürütme ve bilgi türetme fırsatı sağlar.
Derin öğrenmede denetimsiz öğrenmenin katkılarından faydalanarak sınıflandırma benzeri denetimli görevlere destek sunulabilir. Hali hazırda çok büyük miktarda işaretlenmemiş veri kümeleri bulunmaktadır. Bunlar üzerinden eğitilecek olan denetimsiz bir öğrenici ile dil modeli, kelimelerin semantik mesafeleri vb çıktılar üretilebilir. Bu çıktılar sınıflandırma probleminde girdiler ile beraber kullanılarak, dile veya çalışma alanına dair ön bilgiler de değerlendirmede yardımcı olabilir. Bir örnek vermek gerekirse, klasik makine öğrenmesi yöntemleri ile oluşturulan bir sınıflandırıcıda veri seti üzerinden oluşturulan sözlükte (vocabulary) görülmeyen bir sözcük ile karşılaşıldığında, tahminleme esnasında bu kelime hiç hesaba katılamaz. Ancak derin öğrenmenin getirdiği dile dair ön bilgilerin kullanımı ile o kelime hiç görülmemiş olsa bile, vektörel gösterimi ile eğitim setinden karşılaşılmış olan ve benzeri anlama gelen kelimelerden bir fikir yürütülerek tahminlemede bu sözcük de kullanılabilmektedir.
Bu derin öğrenmenin en önemli avantajlarından biridir, öğrenilen bilgiler kompozisyon yoluyla seviye bazında inşa edilir. Daha düşük temsil düzeyi genellikle görevler arasında paylaşılabilir. İnsan dilinin özyinelemesini doğal olarak ele alır. İnsan cümleleri belirli bir yapıya sahip kelimelerden ve ifadelerden oluşur. Yani insanlar bir cümleyi kurarken aslında kelimelerin dizilimi çok fazla bilgi barındırmaktadır ve bilgi bu diziler üzerinden akmaktadır. Klasik makine öğrenmesi yöntemlerinde çok popüler olan kelime çantası (bag-of-words) yönteminde bu bilgi akışını temsil etmek ne yazık ki mümkün olmamaktadır. Derin öğrenme, özellikle tekrarlayan sinir ağları, dizi bilgisini çok daha iyi bir şekilde yakalayabilir.
Veri
Bu eğitici blogda, kodları kendi verimizi kullanarak tasarladık, siz de kodları denemek/geliştirmek için kendi veriniz veya aşağıda paylaştığımız açık kaynak veri setlerini kullanabilirisiniz:
Müşteri geri bildirimlerinden toplanan verilerimiz 17979 içerik ve 5 etiketten oluşmaktadır, etiketler aşağıdaki gibidir.
- kalite
- tavır ve davranış
- geri bildirim
- kullanım
- fiyat
Makine Öğrenmesi Kurgusu (Show me the code)
Veri Önişlemesi

Veriyi ilk olarak ön işleme ile hazırlamamız gerekmektedir. NLP görevlerinin genelinde kelimlerin benzersizliğini azaltmak için köke indirgeyici (stemmer) kullanılır. Böylece “gitmek”,”gidiyor”, ve “gidecek” kelimeleri ‘git’ köküne indirgenerek yazılacaktır. Bu işlem parçaları biraz anlamsızlaştırabilir, kelimenin hangi durumda olduğu bilgisini kaybettirebilir ama yine de sonuçlar kısmına baktığımızda köke indirgeyicinin sınıflandırmaya büyük katkı sunduğunu görebiliriz. Ancak köke indirgemede optimizasyon diğer tüm problemlerde olduğu gibi önemlidir. Çünkü köke indirgemede amaç ortak temisili arttırırken, bilgi kaybını önlemek olmalıdır. Örneğin, basitçe, bir kelimenin ilk 4 karakteri kökünü temsil eder varsayımı ile ortaya konacak köke indirgeyici ortak gösterimi yüksek oranda arttıracaktır ancak öyle örneklerde de bilgi kaybına sebep olacaktır. Mesela “denir” ve “deniz” kelimeleri bu varsayıma göre aynı “deni” kökünde temsil edilecektir. Oysa her iki kelime birbirinden çok uzak kavramları ifade etmektedir.
Köke indirgeyici için örnek bir kod bölümünü aşağıda bulabilirsiniz.
Ardından eğitim verimizi iki kısma bölüyoruz, amacımız sınıflandırıcımızı değerlendirebilmek olacaktır. Bir parçası (genelde büyük olan) eğitim, diğer parçası ise test verisi olarak kullanılacaktır.
- Eğitim verisi: Üzerinden sınıflandırıcının eğitileceği veri setidir.
- Test verisi: Modelin başarımını ölçmek için kullanılan sınama kümesi olacaktır. Bu veri eğitim esnasında sınıflandırıcı tarafından hiç görülmemelidir. Aksi taktirde vereceği olduğu kararların değerlendirmeye bir katkısı olmayacaktır. Taraflı bir değerlendirme yapılacağı düşünülebilir.
Kelimelerin makine öğrenmesi algoritmaları tarafından kabul edilebilmesi için vektörel gösterime dönüştürülmesi gerekmektedir.
Etiket Gücü Kümesi yaklaşımıyla Logistic Regression modülünü eğitelim
modelimizi eğittikten sonra deneyebiliriz
Derin Öğrenme Mimarisi (Deep Learning Model Architecture)
Dikkat mekanizmaları ile birlikte hangi kelimelerin sonucun üretilmesinde daha etkili olduğuna karar verip ona göre o kelimelerin ağırlıklarını günceller. Ayrıca görselleştirmeye izin vererek modelin kararlarının daha anlaşılır olmasını sağlayan bir tekniktir.
Bunu okuyabilirsiniz https://www.aclweb.org/anthology/P16-2034.pdf
Ürettiğimiz modelin mimarisi aşağıdaki gibidir:
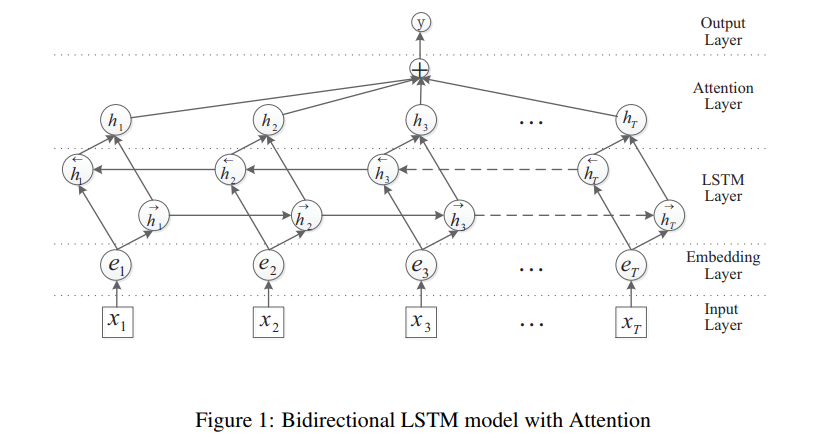
Yukarıda bahsedilen modelde kullanılan dikkat mekanizmasının (attention mechanism) sayesinde, metnin hangi bölümlerinde atama yapılan sınıfa dair daha fazla bilgi olduğu da görselleştirilebilmektedir (highlighting). Buna dair bazı örnekleri görselleştirmesi ile aşağıda bulabilirsiniz.





Artiwise Analytics ile Sınıflandırıcı Eğitme
Ayarlarını kendiniz belirleyebileceğiniz modüller oluşturabilirsiniz.
Oluşturduğunuz modül üzerinde:
- Özellik gösterim (feature representation) yönteminizi (terim frekansına göre, var olup olmama durumuna göre vs)
- Özellik seçimini (feature selection) hangi yöntemle yapacağınızı (ki kare, ortak bilgi vs)
- Verileri bir metin için tek sınıfa mı birden çok sınıf atamasına mı izin vereceğinizi belirleyebilirsiniz.
Modüle verilerinizi dosya olarak veya api üzerinden istediğiniz sınıflandırma bilgisi ve ek bilgilerle beraber yükleyebilirsiniz.
Arayüz üzerinden verilerinizi eğittikten sonra genel veya kategori bazında
- Doğruluk, kesinlik, anma
- Anahtar kelimeler
- Karışıklık matrisi gibi istatistiksel bilgileri görüntüleyebilirsiniz.
Test sekmesinden eğittiğiniz modüle metin yollayarak oluşan kategorileri ve hangi kategorilerin hangi oranlarla tahmin edildiğini gözlemleyebilirsiniz.
Bunlara ek olarak veri analizi, kural ekleme, kategori düzenleme gibi pek çok manipülasyonu da arayüz üzerinden kolaylıkla yapabilirsiniz.
Referanslar
https://www.kdnuggets.com/2018/04/why-deep-learning-perfect-nlp-natural-language-processing.html
https://towardsdatascience.com/multi-label-text-classification-5c505fdedca8